
redis
redis常用5种基本类型:string,hash.list,set,zset
HypeLoglog:二进制存储0,1(存在)允许一定的错误率,大概8%(不确定)。
布隆过滤器:通过多个hash函数到bitmap上,一般用了解决缓存穿透问题(大量请求缓存中不存在的数据,去请求数据库);缓存雪崩(缓存大量同时失效,去请求数据库)随机设置过期时间
redis设置过期时间: 定期删除(redis默认每隔100ms去随机扫描设置了过期时间的key,如果过期就进行删除)和惰性删除(每次使用之前都去查询下是否过期,过期进行删除)
持久化:
事务: MULTI、EXEC、WATCH ;lua脚本;事务不能回滚,redis最终一致性
淘汰机制:
1.设置过期时间内最少使用的数据2.所有数据最少使用---常用3.设置过期时间随机淘汰4.所有数据随机淘汰5.快要过期数据进行淘汰6。不淘汰,写入数据报错,几乎不用
Zookeeper
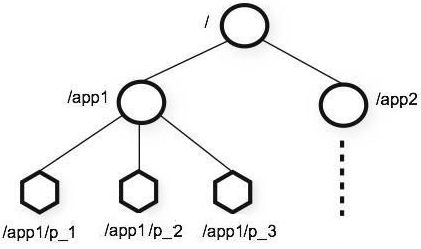
数据结构:znode树形结构,数据存放在内存中,zk可以实现高吞吐量和低延迟,适合读多写少
使用场景:
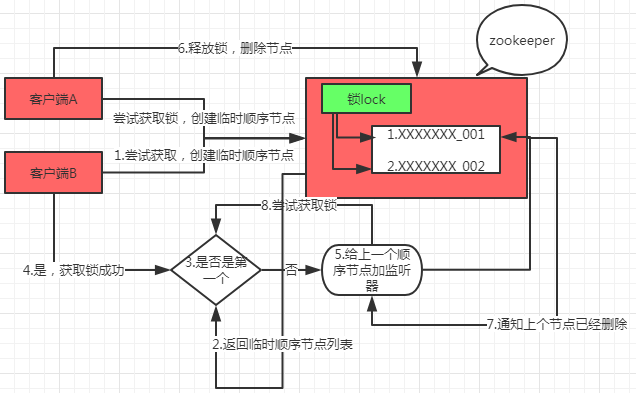
1.分布式锁实现:
2.存储-znode 元数据(version 当前数据的版本,cversion 上个节点的版本,aversion 当前acl版本)
3.集群中的注册中心
三种角色:领导者,追随者,观察者(不参加选举,提供读的能力,提升集群的读性能)
zab协议:保证数据一致性的协议/算法,单调一致性,定义三种节点状态(观察者,领导者,追随者(不参与选举))
zookeeper选举过程主要经过三个步骤:1.选举通过各个节点比较最大的事务zxid和节点信息选出准leader2.发现发现最大事务zxid和事务日志,根据事务日志准leader更新日志3.同步最新事务zxid和事务日志同步到从节点,当一半确定同步,准leader变成leader4.广播 二阶段提交客户端写入请求给任意从节点,从节点将写入请求转发给主节点(1)客户端发送写请求,主节点接收写请求,生成单调递增的事务id和事务日志,将事务id和事务日志同步给从节点,从节点写入日志成功后,返回ack消息给主节点(2)当主节点收到从节点一半的ack消息,主节点返回成功给客户端,并且发送commit请求给从节点特点:顺序一致性,原子性,单一系统映像,可靠性(更改效果持久化)
Znode:元数据data,子节点引用child,访问权限ACL,事务id和版本号和时间戳stat;
Znode并不是用来存储大规模业务数据,而用于存储少量状态和配置信息
分布式锁三种实现方式:
1.数据库建立唯一索引,同时提交到数据库,数据库保证只有一个提交成功,锁表。缺点:强依赖性,如果单点数据库挂了,整个业务系统都无法使用(主从同步);锁没有失效时间,如果解锁失败,导致锁记录一直在数据库中,其他线程无法获取锁(定时清理过期数据);锁非重入,同一个线程未释放锁之前无法再次获取锁,因为记录以及存在(while循环,直到成功获取锁);非阻塞,插入失败会sql报错,没有获取锁的队列不能进入排队队列,要想获取锁只能再次触发获取锁的操作(在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。)2.redis setnx 原子性操作,设置过期时间,分布式下用redlock3.zookeeper分布式锁实现的复杂性角度(从低到高): Zookeeper >= 缓存 > 数据库性能角度: 数据库-> Zookeeper ->缓存可靠性角度: 数据库> 缓存 > Zookeeper